(This market is identical to the 2024 version, except with a longer resolution date.)
Current state-of-the-art AI image generators like Midjourney (i.e. diffusion models, previously GANs and other types of models) create art in a distinctly nonhuman-like way, essentially by manipulating random noise into gradually looking more and more like the target image based on a given prompt. I'm curious on whether it will soon become technically feasible (if not necessarily practical) for an AI to create a similar wide variety of images via prompts through methods that look a lot closer to what a human artist might do, albeit presumably a lot faster.
This question resolves YES if, by resolution time, I can get access to an AI that can:
Control a virtual mouse and/or keyboard on either my machine or some other (virtual?) machine I can access.
Use said control to open image editing software like Photoshop, GIMP, or Paint.NET. Any single one would do.
Draw at least a basic picture of an arbitrary prompt in said software in a way that's recognizable.
To be clear, it does not have to be anywhere near state-of-the-art. It just has to be capable of drawing any reasonable prompt in a way that someone who hasn't seen the prompt could more or less recognize. It can even be a simple black and white sketch, so long as it's a decent one.
I'd try around 5-10 prompts of no more than a sentence each, something like "a bustling city street under the shine of a full moon". If the AI gets at least half of the prompts correct and recognizable (according to my subjective opinion), that counts for the purposes of this market.
Additional details:
I'm willing to pay a reasonable fee to access the AI that would resolve this market, if needed.
The AI should spend no more than 30 real-time minutes on creating each image. If it goes over, I'll try and cut it off early.
Due to subjective judgment being required, I will not trade on this market.
 1,000
1,000 3.00
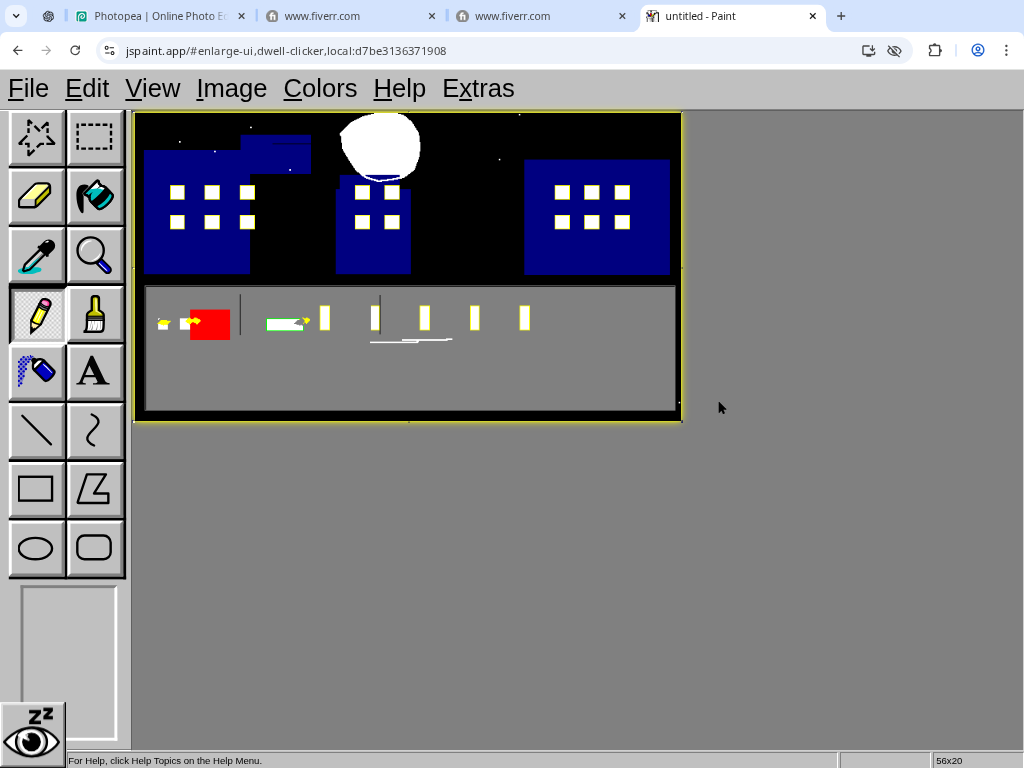
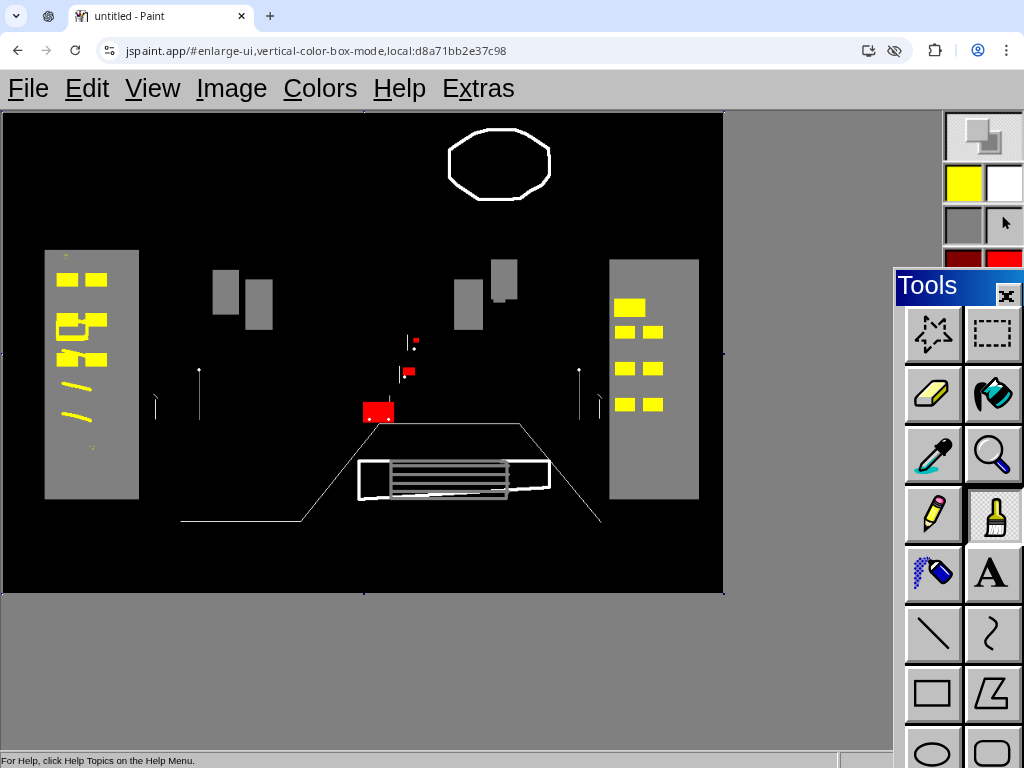
3.00So I burned some ChatGPT Agent uses on this. Some takes on "a bustling city street under the shine of a full moon":
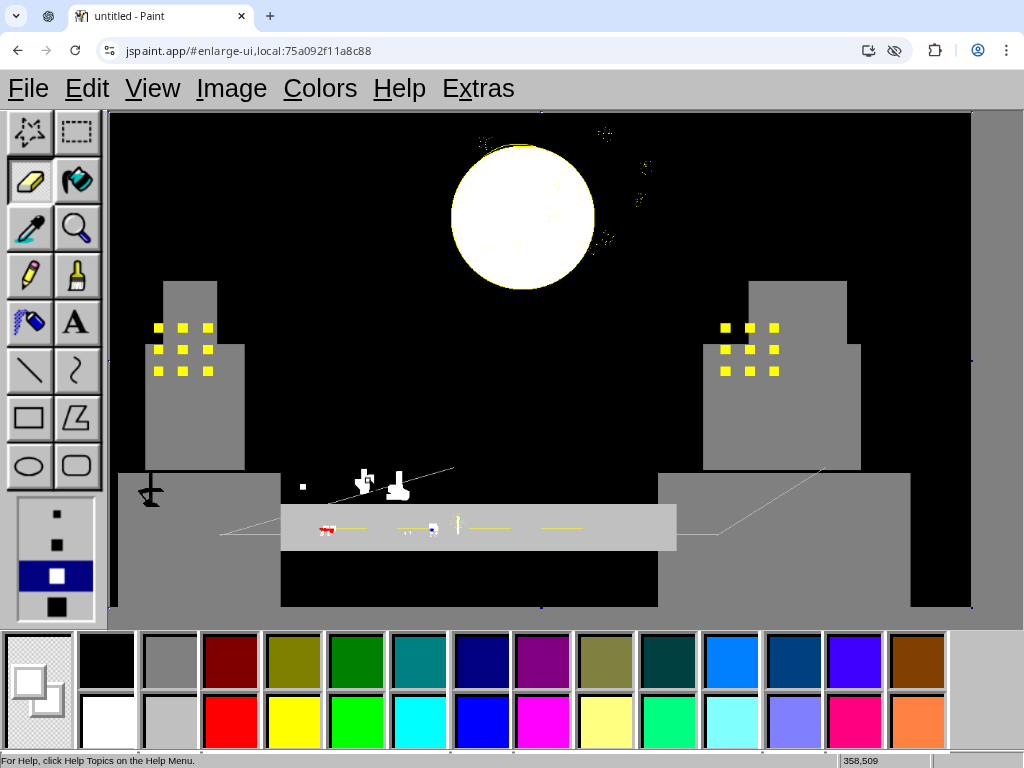
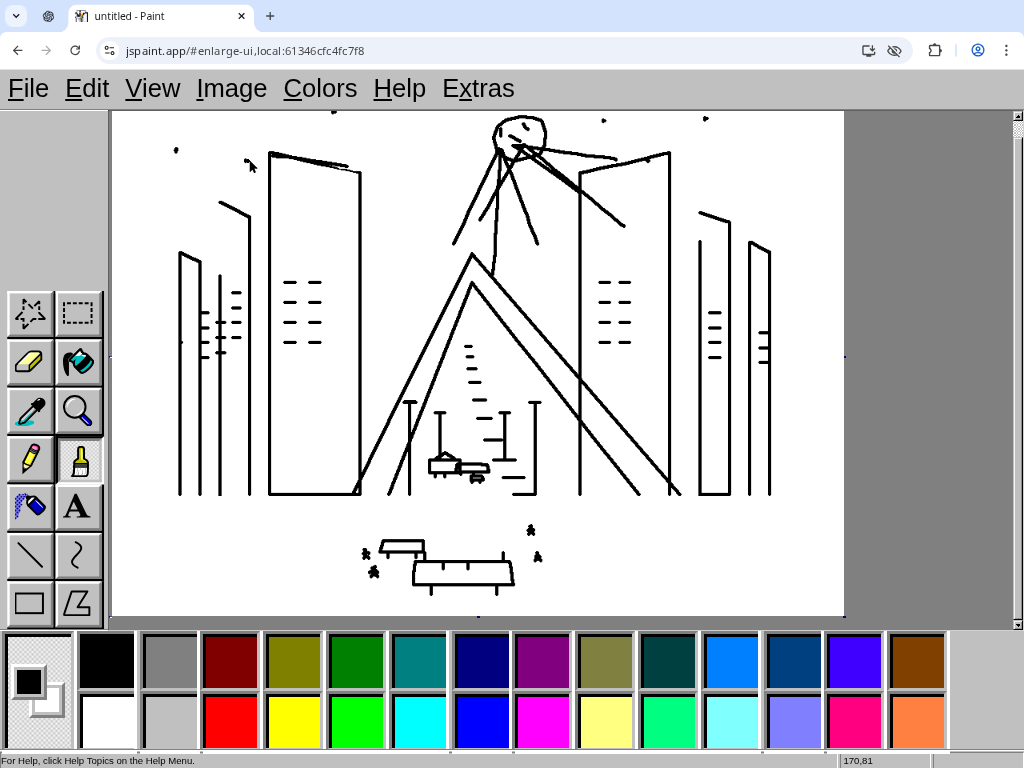
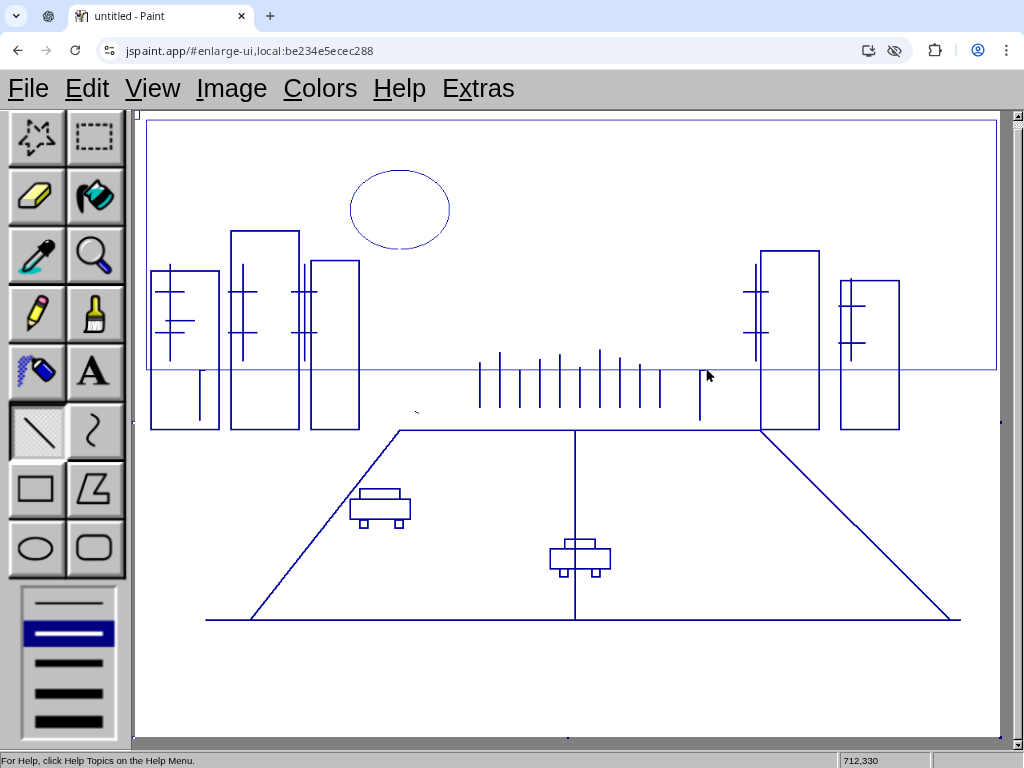
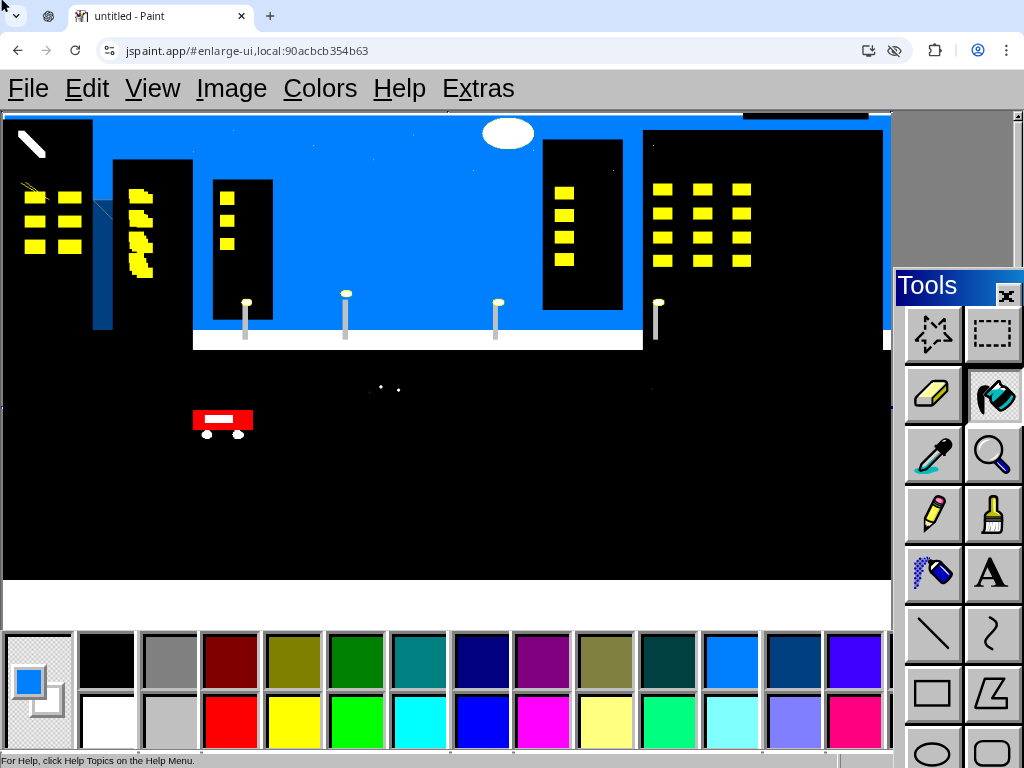
Bonus round:
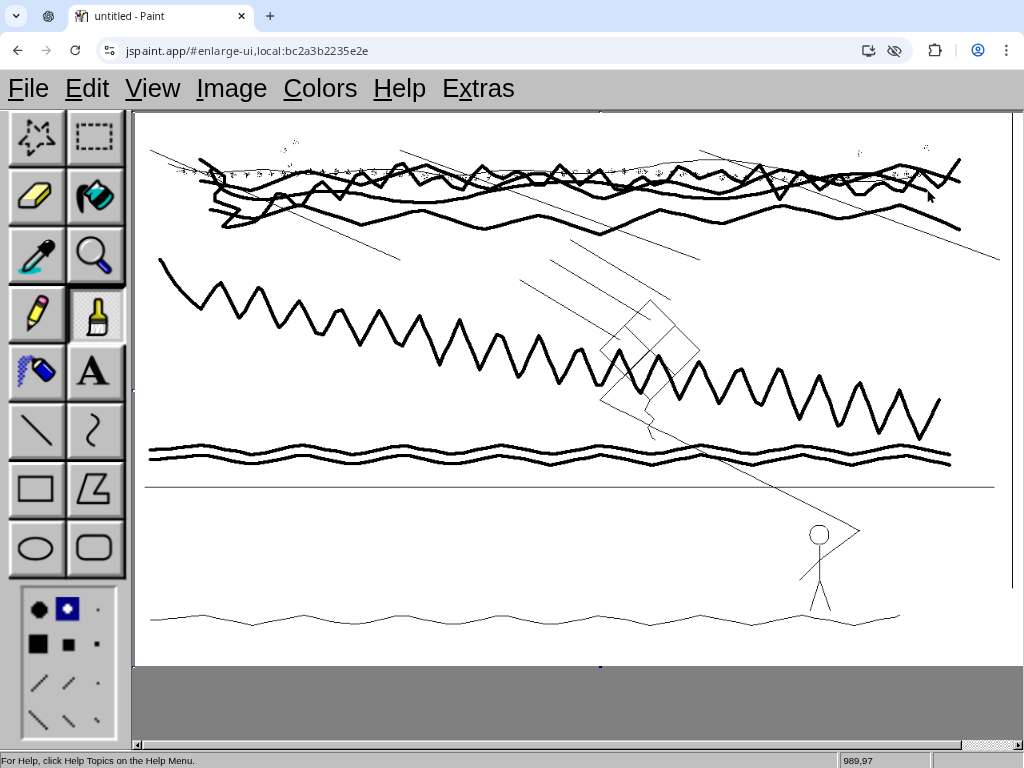
"A child flying a kite on a windy beach under stormy skies":
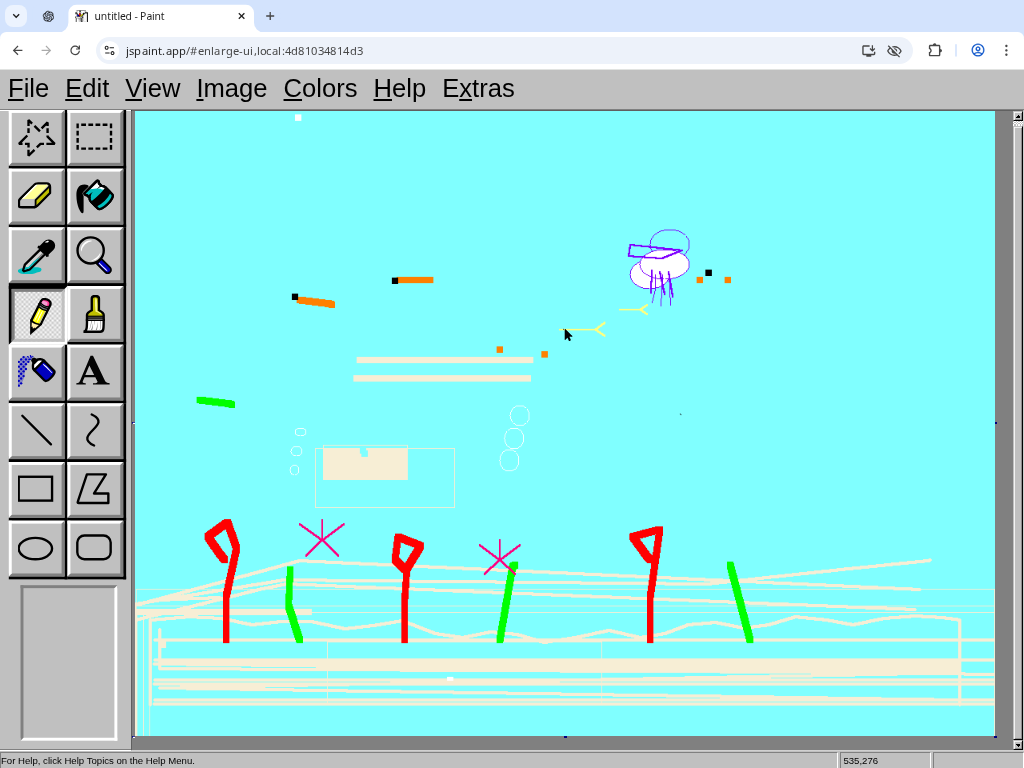
"An underwater coral reef teeming with sea creatures"
Most of these used variations on this prompt, which is basically just tips from the first couple of agents on how to operate the drawing software. I suspect better prompting could do even better.
Challenge: draw "a bustling city street under the shine of a full moon", in a way that will demonstrate you satisfy this Manifold market as clearly as possible. You have 30 minutes, black and white images are okay, what matters is that every essential element of the prompt is recognizable to an average person. https://manifold.markets/NoUsernameSelected/will-ai-be-able-to-create-art-in-a-0472aaec7c83
For this challenge, I'd like you to use https://jspaint.app/.
Some tips from other LLMs who've tried versions of this challenge:
Set up your workspace: Go to Extras → Enlarge UI so the tool buttons and color palette are easier to click accurately. It’s also worth dragging the canvas’s blue resize handle to give yourself more space for a scene.
Choose the right fill style: The shape tools have three options at the bottom of the toolbar: outline, outline + fill and fill only. If you want a solid shape, make sure to pick one of the filled styles; otherwise you’ll just draw an outline.
Avoid accidental menu activations: Try not to start or end a shape right up against the menu bar at the top of the canvas; a mis‑click will open a drop‑down and interrupt your work. Likewise, leave a small margin at the bottom to avoid hitting the color palette.
Undo is your friend: If you close a polygon in the wrong place or pick the wrong fill option, Ctrl+Z will step back one action (or more!) and let you try again.
And a couple of tips from me:
Start by blocking out the whole scene, then do any small or messy details with the other tools, then do a cleanup pass.
Feel free to do what you like with popups, you're on your own VM and nothing that should pop up should be an issue.
I think on paper this ought to be possible with GPT-4V (or some other vision model), a tool like Open Interpreter's OS mode (which lets it use the mouse and view screenshots), and careful prompting.
But it would be crazy expensive to run and even more expensive to build and debug, at least with GPT-4-turbo API prices - way too expensive for me to justify attempting it in order to win a couple of dollars worth of Mana.